SciDataCon2014 Open Science Roundup
Jenny Molloy - November 18, 2014 in External Meetings, Featured, Research, Tools
SciDataCon 2014 was the first ever International Conference on Data Sharing and Integration for Global Sustainability jointly organised by CODATA and World Data Systems, two organisations that form part of the International Council for Science. The meeting was held 2-5 November in New Delhi and I had the pleasure of staying in the peaceful, green campus of IIT-Delhi within walking distance of SciDataCon2014 at the adjacent and equally pleasant Jawaharlal Nehru University (JNU).
It was a jam-packed week but I’ve tried to pick out some of my personal highlights. Puneet Kishor has also blogged on the meeting and there was an active Twitter feed for #SciDataCon2014 .
Text and Data Mining Workshop
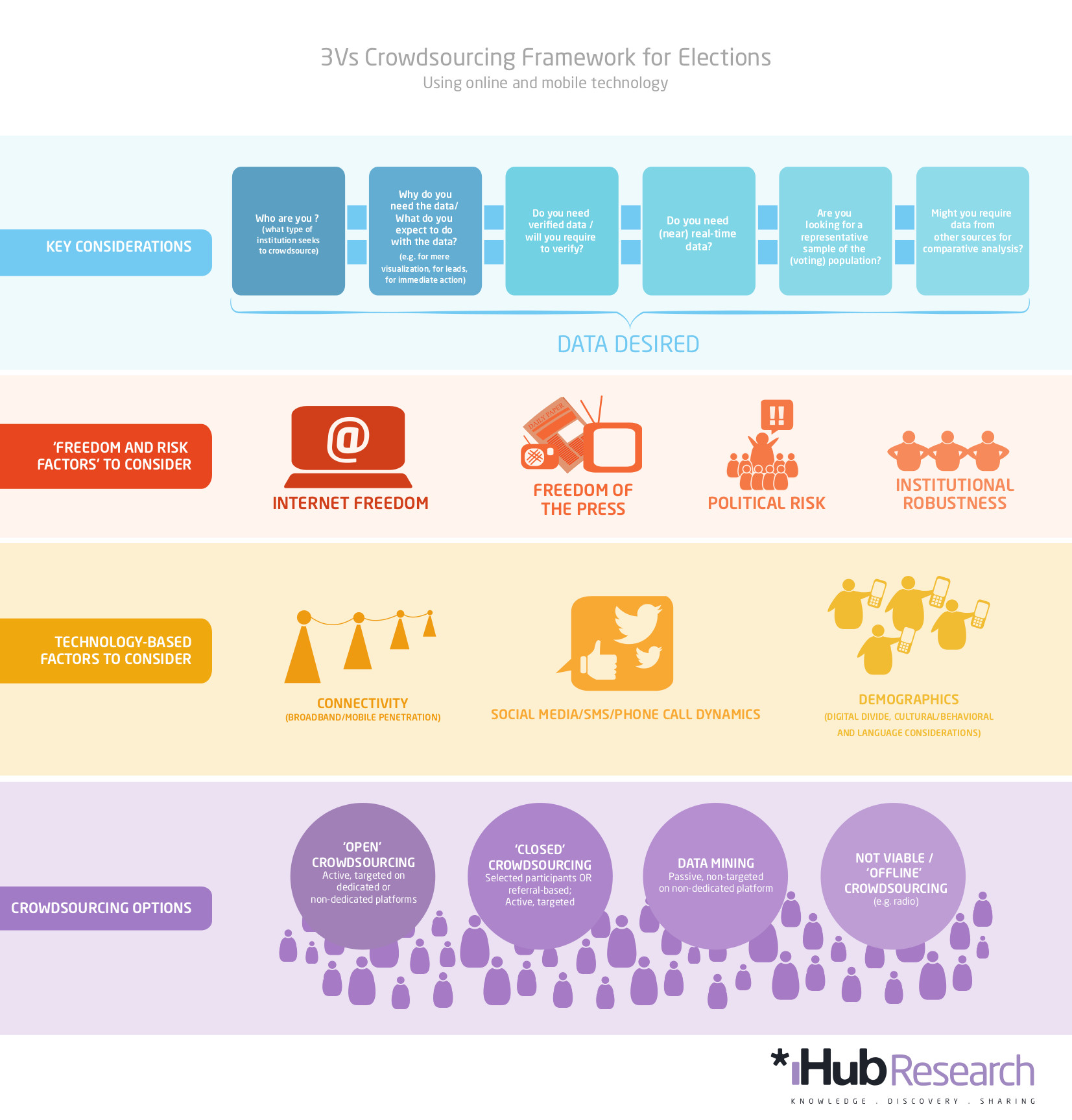
Open Data Initiatives
Data from the People for the People
Summary
Bonus slide decks

Photo by Puneet Kishor published under CC0 Public Domain Dedication
Text and Data Mining Workshop
On Sunday 2 November I ran a workshop with Puneet Kishor of Creative Commons as a joint venture with Open Knowledge and ContentMine. Armed with highlighters, post-it notes and USB-stick virtual machines, we led a small but dedicated and enthusiastic group of immunologists, bioinformaticians, plant genomics researchers and seabed resource experts through the basics of content mining.

Photo by Puneet Kishor published under CC0 Public Domain Dedication
We covered what it means, when it is legal to content mine and more broadly some of the policy and legal frameworks which impact access to and rights of reuse for the scientific literature. We hand annotated entity types in two papers about lion evolution and Aspergillus fungi. This aimed to get people thinking about patterns and how to program entity recognition – what instructions does a computer require to recognise what our brain categorises easily? Swapping over the papers showed 80-90% inter-participant agreement in entity mark-up suggesting a reasonable precision and recall rate for our content mining humans!

Photo by Puneet Kishor published under CC0 Public Domain Dedication
Everybody managed to scrape multiple Open Access publications and extract species names, we also discussed potential collaborations and had a virtual visitor from afar, Peter Murray-Rust. The overwhelming feeling in the room was once of dismay at the restrictions on reuse of academic content but optimism about the potential uses of content mining – we hope that an excellent collaboration opportunity around phytochemistry will come to fruition!

Open Data Initiatives
![]()
Several sessions over the conference highlighted how far we still have to go in terms of data sharing and particularly the challenge of gaining political will required for data sharing for global sustainability. Waltraut Ritter, a member of the active Open Knowledge local group Open Data Hong Kong, presented a paper co-authored with Scott Edmunds and others, making the case to policy makers that open data can support science and innovation. There is no guidance from the Hong Kong University Grants Committee on dissemination of research data resulting from its 7.5 billion HKD annual funding pool. Data sharing was explicitly flagged as low priority in 2011 and on enquiry in 2014 Open Data HK were informed that this assessment had not changed. Arguments to appeal to policy makers are clearly required in these situations and Waltraut expanded on a few during the talk.
Exploring the complexities of sharing data for public health research, Sanna Meherally reported on a qualitative study examining the ethical and practical background to potential research data sharing, involving five sites in Asia and Africa, and focusing on stakeholder perspectives. A key takeaway message was the importance of considering cultural barriers to implementation of funder data policies. Chief concerns raised in interviews were confidentiality, the potential for data collection efforts to be underplayed and the need to give something back to research participants. That the latter point was raised by so many researchers interviewed is encouraging given the title of the next day’s session ‘Data from the people for the people’, which was another focus of SciDataCon.
Data from the People for the People – encouraging Re-use and Collaboration
This double session focused on citizen science projects around topics related to sustainability, including biodiversity and climate change. Norbert Schmidt introduced projects in the Netherlands to monitor air quality while Raman Kumar from the Nature Conservation Foundation introduced a range of bird and plant ecology citizen science projects in India such as eBird, MigrantWatch and SeasonWatch. You can find the full session list here.

Cumulative hours of birding as of Sep 214 through the eBird India citizen science initiative
 Tyng-Ruey Chuang tackled some of these issues in his talk on ‘Arrangements for Data Sharing and Reuse in Citizen Science Projects‘. He asked projects to compare themselves to Wikipedia in terms of openness, participation and tools. For instance, does your project retain or strip metadata from contributed images? Tyng-Ruey also emphasised informed participation – clearly state if citizen contributions are prima facie uncopyrightable or ask agreement for open licensing. This chimed with earlier points by Ryosuke Shibasaki about the need for citizen ownership of contributed data and agency to make informed decisions about its use.
Tyng-Ruey Chuang tackled some of these issues in his talk on ‘Arrangements for Data Sharing and Reuse in Citizen Science Projects‘. He asked projects to compare themselves to Wikipedia in terms of openness, participation and tools. For instance, does your project retain or strip metadata from contributed images? Tyng-Ruey also emphasised informed participation – clearly state if citizen contributions are prima facie uncopyrightable or ask agreement for open licensing. This chimed with earlier points by Ryosuke Shibasaki about the need for citizen ownership of contributed data and agency to make informed decisions about its use.
The talk ended with a call to action, as the Open Definition was practically quoted and Tyng-Ruey called for raw data, now! He’s in good company at Open Knowledge!

Summary
The sessions above are only a small subset of the conversations happening across the whole programme and papers are available online for all sessions. There were many demands for more open data, from Theo Bloom using her keynote to call for the abolition of data release embargos to Chaitanya Baruo revealing that Indian geology students are using US data because India does not make its own data available for open academic research. However, there were also excellent case studies of the reuse of data and its value. It would have been interesting to see some more cross-cutting sessions including all of the data collection and sharing cycle, but that will need to wait for 2016! This is a thoroughly recommended conference for data scientists and managers as well as domain experts and has notable participation from the global South, which is excellent and enriches the perspectives discussed.
Finally, I can only apologise for not being able to report on the Strategies Towards Open Science Panel – I was giving a talk at IIT which clashed with the session, but I’ve no doubt some excellent points were raised which will soon be shared!
Bonus slide decks
I couldn’t attend these sessions, but they’re worth a look! First up Susanna Sansone and Brian Hole on data journals: