The great potential of citizen science
anngrand - November 12, 2014 in Featured, Guest Post, Research
This is a guest post by Benedikt Fecher of The Alexander von Humboldt Institute for Internet and Society (HIIG) and is re-posted from the HIIG blog
Citizen science is nothing new
What do Benjamin Franklin, Johann Wolfgang von Goethe, and Francis Bacon have in common?
All were amateur scientists. Franklin invented the lightning rod, Goethe discovered the incisive bone and was moderately successful as an art theorist and Bacon can be considered as nothing less than the father of empiricism, or can he? Either way, the three shared a passion for discovering things in their spare time. None of them earned their pennies as professional scientists, if that profession even existed back then.

Discovery is a matter of thirst for adventure
Citizen science is in fact old hat. It existed long before disciplines existed and could be described as the rightful predecessor of all empirical science. It laid the foundations for what we know today as the scientific method: the rule-governed and verifiable analysis of the world around us. Still, amateurs in science have often become marginalized over the past 150 years, as scientific disciplines have emerged and being a scientist has become a real thing to do (read more here).
Citizen science’s second spring
Today, citizen science is experiencing a second spring and it is no surprise that the internet has had a hand in it. In recent years, hundreds of citizen science projects have popped up, and they’re encouraging people to spend their time tagging, categorizing and counting in the name of science (see here and here). Some unfold proteins in an online game (Foldit), while others describe galaxies from satellite images (GalaxyZoo and here) or count wild boars in Berlin and deliver the numbers to an online platform (Wild boars in the city). Citizen science has moved online. And there are thousands of people in thousand different places that do many of funny things that can alter the face of science. The Internet is where they meet.

Berlin Wall; East Side Gallery
The logic of Internet-based citizen science: Large scale, low involvement
Citizen science today works differently to the citizen science of Goethe’s or Franklin’s time. The decentralised and voluntary character of today’s citizen science projects questions the way research has been done for a long time. It opens up science for a multitude of voluntary knowledge workers that work (more or less) collaboratively. In some respect, the new kind of citizen science is drawing on open innovation strategies developed in the private sector. In their recent Research Policy article, Franzoni and Sauermann refer to this type of amateur science as crowd science. The the term is extremely effective at capturing the underlying mechanics of most citizen science projects, which involve low-threshold-large-scale-participation. Today, participation of volunteers in science is scalable.
The advantages of citizen science
When it comes to data collection, social participation and science communication, citizen science is promising.
For scientists, it is an excellent way to collect data. If you visit one of the citizen science directories (for example here and here) and scroll through the projects, you will see that most of them involve some kind of documenting. These citizen scientists count rhinoceros beetles, wild boars, salamanders, neophytes, mountains and trees. There is nothing that cannot be quantified, and a life solely devoted to counting the number of rhinoceros beetles in North America would indeed be mundane for an individual scientist, not to speak of the travel expenses. Citizen scientists are great data sensors.
For citizen scientists it is a way of partaking in the process of discovery and learning about fields that interest them. For example, in a German project from the Naturschutzbund (German Society for the Conservation of Nature), sports divers are asked to count macrophytes in Northern German lakes. The data the divers collect help monitoring the ‘state of health’ of their freshwater lakes. In follow-up sessions, the divers are informed about the results. The case illustrates how citizen science works. Volunteers help scientists and in return receive first-hand information about the results. In this regard, citizen science can be an excellent communication and education tool.
Citizen science brings insight from without into the academic ivory tower and allows researchers and interested non-researchers to engage in a productive dialogue. This is a much-needed opportunity: for some time now, scholars and policy makers have been saying how challenging it is to open up science and involve citizens. Still, what makes the new kind of internet-enabled citizen science science, is rather the context volunteers work in than the tasks they perform.
The honey bee problem of citizen science
The old citizen scientists, like Franklin, Goethe or Bacon asked questions, investigated them and eventually discovered something, like Goethe did with his incisive bone. In most citizen science projects today, however, amateurs perform rather mundane tasks like documenting things (see above), outsourcing computing power (e.g. SETI@home) or playing games (e.g. Foldit). You can go to the Scientific American’s citizen science webpage and search for the word ‘help’ and you will find that out of 15 featured projects, 13 are teasered help scientists do something. The division of roles between citizens and real scientists is evident. Citizen scientists perform honey bee tasks. The analytic capacity remains with real researchers. Citizen science today is often a twofold euphemism.
That is not to say that collecting, documenting and counting is not a crucial part of research. In many ways the limited task complexity even resembles the day-to-day business of in-person research teams. Citizen scientists, on the other hand, can work when they want to and on what they want to. That being said, citizen science is still a win win in terms of data collection and citizen involvement.
An alternative way to think of citizen science: Small scale, high involvement
A second way of doing citizen science is not to think of volunteers as thousands of little helpers but as knowledge workers on a par with professional researchers. This small-scale type of citizen science is sometimes swept under the mat even though it is equally promising.
Timothy Gower’s Polymath Project is a good case for the small-scale-high-involvement type of citizen science. In 2009, Gowers challenged the readers of his blog to find a new combinatorial proof of the density version of the Hales-Jewett theorem. One has to know, that Gowers is a field medallist in math and apparently his readers share the same passion. After seven weeks, he announced that the problem had been solved with the help of 40 volunteers, a number far too small to count as massively collaborative.
Nevertheless, Gower’s approach was successful. And it designated an form of citizen science in which a few volunteers commit themselves for a longer period to solve a problem. This form of citizen science is fascinating regarding its capacity to harvest tacit expert knowledge that does not reside in a scientific profession. The participation is smaller in scale but higher in quality. It resembles Benkler’s commons-based peer production or the collective invention concept from open innovation.
The core challenges for this kind of citizen science is to motivate and enable expert volunteers to make a long-term commitment to a scientific problem.
Both strategies, the large scale low involvement participation as well as the small scale high involvement participation have the capacity to alter science. The second however would be a form of citizen science that lives up to its name. Or did you never want to discover your own incisive bone?
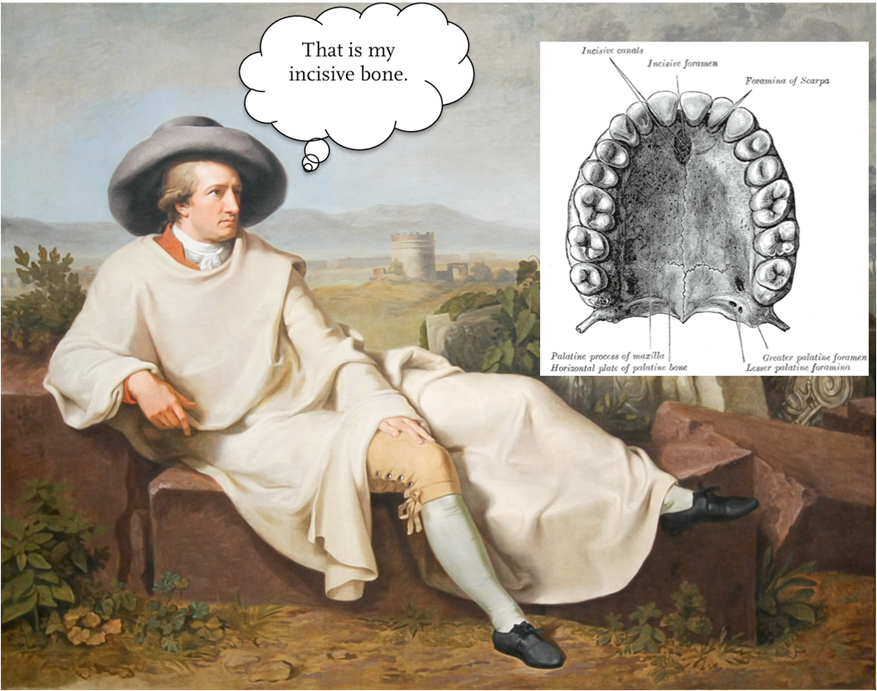
Goethe and the incisive bone
Pictures
- Franklin with kite: Franklin’s Experiment, June 1752
- Wall: Own picture
- Goethe dozing on stones: Goethe in the Roman Campagna (1786) by Johann Heinrich Wilhelm Tischbein.
- Incisive bone, Gray’s Anatomy, 1918
Thanks to Roisin Cronin, Julian Staben, Cornelius Puschmann, Sascha Friesike and Kaja Scheliga for their help.







{kind=link}
{kind=link}
{kind=link}