What’s new in Head Start?
Peter Kraker - April 29, 2014 in Panton Fellowships
The past couple of months I have been working on the open source visualization Head Start in the context of my research stay at University of Pittsburgh. Head Start is intended for scholars who want to get an overview of a research field. They could be young PhDs getting into a new field, or established scholars who venture into a neighboring field. The idea is that you can see the main areas and papers in a field at a glance without having to do weeks of searching and reading. You can find more information in my last blog post on the system.
If you read this post, you already know that Philipp Weißensteiner introduced a timeline visualization to the repository that lets you compare different datasets in a single view. I finished the integration of the timeline visualization, making it possible to review all datasets both in the regular and the timeline view. I was also busy consolidating the code and fixing the occassional bug along the way. The biggest change in version 2.5, however, is the introduction of a server component to Head Start. So far, Head Start consisted of a pre-processing system for generating the data, and an HTML5 interface for visualizing the data. There was no way of manipulating the visualization after it had been loaded. The new server component consists of REST-ful webservices and a PHP backend to deal with dynamic requests.
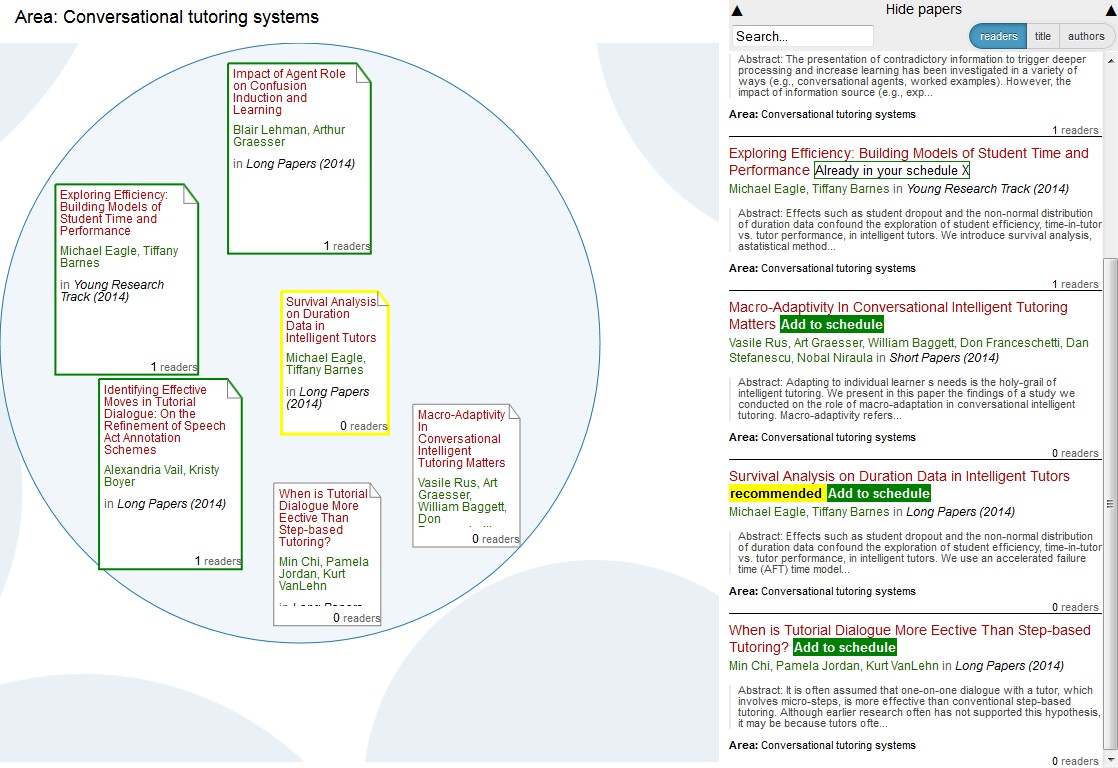
The server component proved very useful during the integration of Head Start with Conference Navigator 3, developed by the great folks of the PAWS Lab here in Pittsburgh. Conference Navigator is a nifty scheduling system that allows you to create a personal conference schedule by bookmarking talks from the program. The system then gives you recommendations for further talks based on your choices. Head Start will be used as an alternate way of looking at the topics of the conference, and to give better context to the talks that you already selected and the talks that are recommended for you. To do that, Head Start dynamically loads bookmarking and recommendation data from the CN3 database.
What’s next? First of all, the system will be evaluated with users in one of the upcoming conferences that Conference Navigator supports. Furthermore, I would like to move the preprocessing systems from an offline to an online solution, thus enabling it to load live content from APIs.
If any of the above got you interested, here is the link to the Github repository. As always, please get in touch if you have any questions or comments, or in case you want to collaborate on this project.